[Must Learning with R_2] Ch3. 기본문법 2단계 연습문제
Wikidocs에 올라와있는 Must Learning with R 을 참고하며 방학동안 부족한 R programming 공부를 하고있습니다. 책에 나와있는 연습문제를 정리하려 합니다.
Ch3. 기본문법 2단계
연습문제1
HR 데이터의 행의 수, 열의 수를 구하시오.
HR = read.csv('D://HR_comma_sep.csv')
dim(HR)
결과
> HR = read.csv('D://HR_comma_sep.csv')
> dim(HR)
[1] 14999 10
연습문제2
salary변수의 strings에 대해 답하시오.
str(HR$salary)
결과
> str(HR$salary)
Factor w/ 3 levels "high","low","medium": 2 3 3 2 2 2 2 2 2 2 ...
연습문제3
salary변수에 대하여 low는 1, medium은 2, high는 3의 값을 가져 서열정보를 가지게 하는 salary_New 변수를 만드시오.
HR$salary_New = ifelse(HR$salary == 'high', 3,
ifelse(HR$salary =='medium', 2,1))
summary(HR$salary_New)
결과
> HR$salary_New = ifelse(HR$salary == 'high', 3,
+ ifelse(HR$salary =='medium', 2,1))
> summary(HR$salary_New)
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.000 1.000 2.000 1.595 2.000 3.000
연습문제4
Salary_New 값이 2이면서 left는 1인 직원들만 뽑아 Medium_Left라는 새로운 데이터프레임을 만드시오.
Medium_Left = subset(HR, salary_New == 2 & left == 1)
print(xtabs(~ Medium_Left$salary + Medium_Left$left))
결과
> Medium_Left = subset(HR, salary_New == 2 & left == 1)
> print(xtabs(~ Medium_Left$salary + Medium_Left$left))
Medium_Left$left
Medium_Left$salary 1
high 0
low 0
medium 1317
연습문제5
Medium_Left 데이터에 대해 department변수 별로 time_spend_company의 평균을 구하여, Time_spend_Mean이라는 데이터프레임을 만드시오.
SS2 = ddply(HR,
c('department'),summarise,
Time_spend_Mean = mean(time_spend_company))
print(SS2)
결과
> SS2 = ddply(HR,
+ c('department'),summarise,
+ Time_spend_Mean = mean(time_spend_company))
>
> print(SS2)
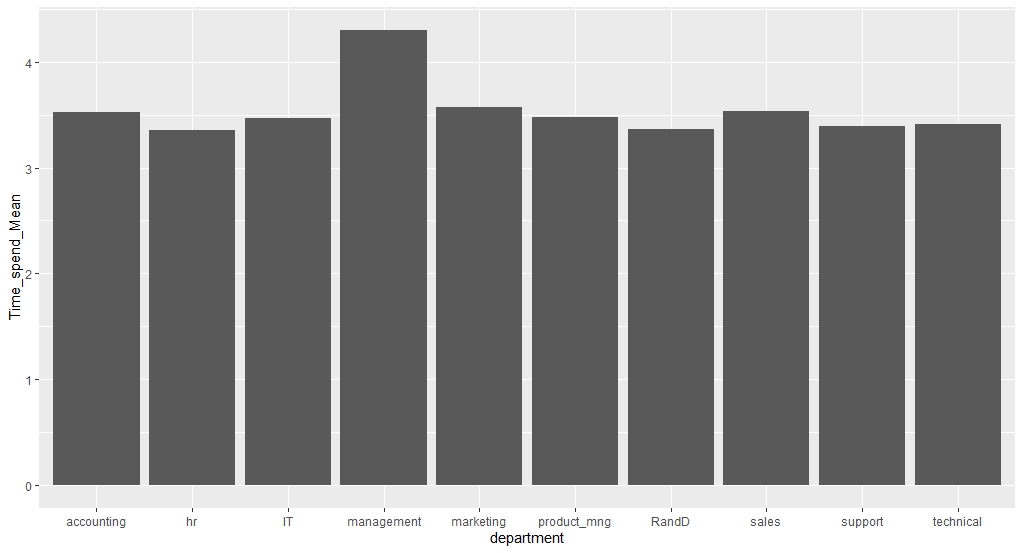
department Time_spend_Mean
1 accounting 3.522816
2 hr 3.355886
3 IT 3.468623
4 management 4.303175
5 marketing 3.569930
6 product_mng 3.475610
7 RandD 3.367217
8 sales 3.534058
9 support 3.393001
10 technical 3.411397
연습문제6
Time_spend_Mean 데이터프레임을 이용하여 department별 time_spend_company의 평균을 나타내는 막대도표를 그리시오. (stat = ‘identity’ 옵션 활용 필요)
library(ggplot2)
ggplot(SS2,aes(department,Time_spend_Mean)) +
geom_bar(stat='identity')
결과